ADAS developers have been focused on bringing an ever-expanding list of autonomous driving features to market. On this competitive front, intelligent algorithms are no longer the only distinguishing factor that impacts capabilities and performance—hardware has risen to a more prominent role, especially critical as manufacturers steer closer to Level 5, fully autonomous capabilities. Why does hardware matter more now? Because accumulating data is just the first step to empowering ADAS. It’s the data and its latency-free handling in rigorous settings that holds the keys to ADAS safety and success.
Deep learning training and deep learning inference—both data intensive operations—are vital to the ADAS development process. Using large data sets, deep learning training teaches the deep neural network to carry out AI tasks such as image and voice recognition. Deep learning inference leverages that training to predict what new data means. It’s a development process that has evolved based on steadily increasing data requirements—today as much as 4TB per day for a single vehicle—and it requires specialised solutions such as AI edge inference computers. Systems must contain large amounts of high-speed solid-state data storage and be hardened to tolerate exposure to shock, vibration, environmental contaminants, and extreme temperatures, even as they process and store vast amounts of data from various sources. Here, ideal design marries the software-based functionality of deep learning with rugged hardware strategies that are optimised for edge and cloud processing.
Train the model
While deep learning training is often the most challenging and time-intensive method to create AI, it provides the means for a deep neural network (DNN) to complete a task. Many layers of interconnected artificial neurons make up a DNN. These DNNs must learn to perform a specific AI task: speech to text conversion, image categorisation, video classification, or creating a recommendation system. Data is fed to the DNN, which then uses it to predict what the data means.
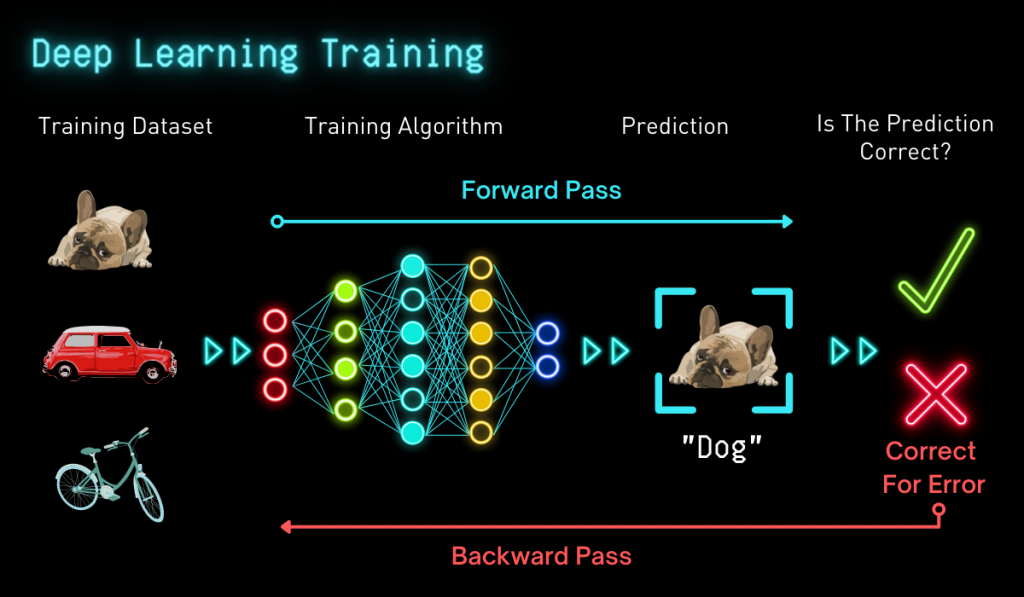
For example, a DNN might learn to differentiate three distinct objects: a dog, a bicycle, and a car. The first step involves compiling a data set that consists of thousands of images, including dogs, bikes, and cars. The next step involves feeding images to the DNN; based on its training, the DNN then determines what the image signifies. Whenever an incorrect prediction is made, the error is corrected and the artificial neurons are amended to enable more accurate inferences in the future. Using this method, the network will likely have greater success each time it is presented with new data sets. This training process is perpetuated until the predictions meet the preferred level of accuracy. From here, the trained model is deemed ready to use additional images to make accurate predictions.
Deep learning training is highly compute-intensive. Training a DNN can often require billions upon billions of calculations. The process relies on hardy compute power able to run calculations in real time. In the data centre, deep neural network training relies on GPUs, VPUs, multi-core processors, and other performance accelerators. These are the ingredients that advance AI workloads with tremendous speed and accuracy.
Put the model to work
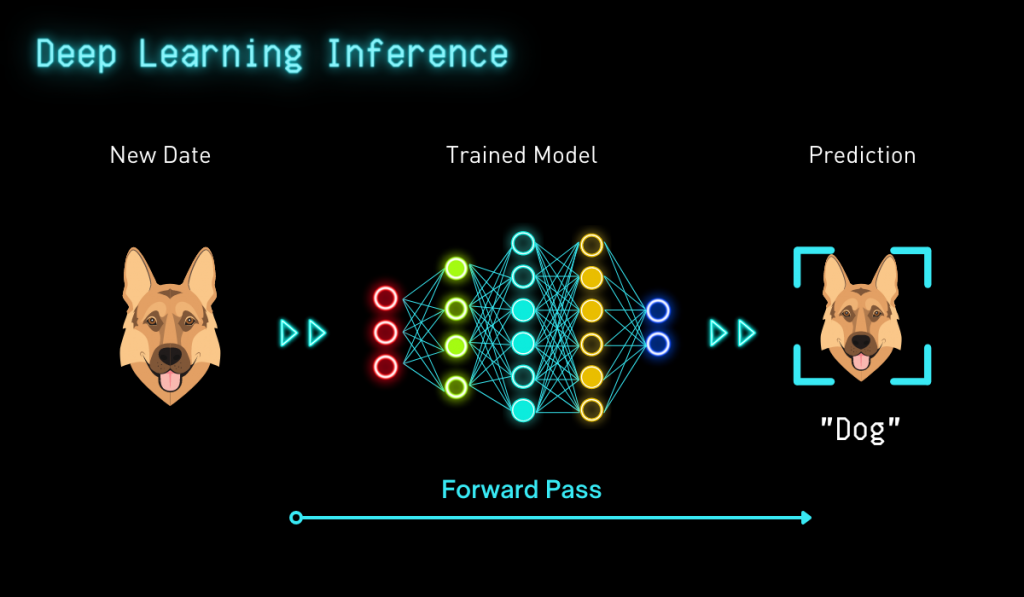
Deep learning inference adds to the value of deep learning training. By using a fully trained DNN, predictions can be made based on brand new data closer to where it’s produced. In deep learning inference, new data, such as images, are added to the network, facilitating DNN classification of said images. For instance, building on the ‘dog, bicycle, car,’ example, new images of dogs, cars, and bikes as well as other objects are loaded into the DNN. The result is a fully trained DNN that can accurately predict what an image represents.
Once fully trained, a DNN can be replicated to other devices. However, DNNs can be extremely large, often including hundreds of layers of artificial neurons that connect billions of weights. Prior to deployment, the network must be adapted to require less memory, energy, and computing power. While a slightly less accurate model, its simplification benefits more than make up for this.
To modify the DNN, one of two methods can be employed; pruning or quantisation. Pruning involves a data scientist feeding data to the DNN and then observing. Problematic neurons are detected and removed without significant impact on prediction accuracy. Quantisation entails reducing weight precision. For instance, decreasing a 32-bit floating-point to an 8-bit floating-point generates a small model that uses fewer compute resources. Either method has negligible impact on model accuracy. The model becomes much smaller and faster, cutting energy use and consumption of compute resources.
ADAS at the edge
A hybrid model has commonly been used for deep learning inference at the edge. An edge computer gathers information from a sensor or camera and transfers that data to the cloud. Data delivered to the cloud, analysed, and returned takes a few seconds, creating latency unacceptable in applications that require real-time inference analysis and detection. Conversely, inference analysis can be performed in real-time via edge computing devices specifically designed for split-second autonomous decision making as well as in-vehicle deployment. Tolerant to myriad power input scenarios, including vehicle batteries, these industrial-grade systems are ruggedised to endure exposure to extreme temperature, impact, vibration, dust, and other environmental challenges. These attributes, coupled with unique high performance, ease many issues related to cloud processing of deep learning inference algorithms.

For instance, GPUs and TPUs fast-track the ability to perform a wide array of linear algebra computations, allowing the system to conduct such operations in tandem. Instead of the CPU running AI inference calculations, the GPU or TPU—both better at math computations—assumes the workload to greatly accelerate inference analysis. In contrast, the CPU is laser focused on running the standard applications and the OS.
Local inference processing removes latency issues and solves internet bandwidth problems associated with raw data transmission, especially large video feeds. Both wired and wireless connectivity technologies, including Gigabit Ethernet, 10 Gigabit Ethernet, Cellular 4G LTE and Wi-Fi 6, support system internet connection in various conditions. Promising 5G wireless technology expands options further with its lightning-fast data rate, far lower latency, and increased bandwidth. These abundant connectivity options enable cloud offload of mission-critical data and accommodate over-the-air updates. With additional CAN bus support, the solution can log vehicle data from both vehicle buses and networks. Real-time insight can be gleaned from information such as wheel speed, vehicle speed, engine RPM, steering angle, and other rich data relaying essential information about the vehicle.
Getting the most out of automotive big data
Automotive big data is here, proven by the sheer scope of data generated by ADAS-integrated or self-driving vehicles. Sensory information from radar, LiDAR, high-resolution cameras, ultrasonic sensors, GPS, and other sensors feeds the various levels of autonomous driving, particularly important as Levels 3, 4 and 5 come into closer view. It’s a big job and it’s only getting bigger – driving designers to strategically blend sophisticated software design and innovative hardware strategies for competitive vehicle performance, passenger wellbeing, and road safety.
About the author: Dustin Seetoo is Director of Product Marketing, Premio Inc.


